
No LLM? No Problem – Run a RAG Bot Locally
How to Build and Run a RAG Chatbot Locally Using Open-Weight Models—No LLM Subscription Needed!


Introduction
If you've read our article How to Create a RAG Chatbot and tried running the repository RAG-base, you might have encountered a common challenge—lack of access to an LLM service such as Anthropic’s Claude or OpenAI’s ChatGPT, or not having an embedding model set up. As a result, running the project locally or working with any RAG solution, not just ours, becomes difficult.
To address this, we've introduced several updates that make it easier than ever to get started—no LLM subscription or complex setup required!
Run Models Locally?
You might be wondering—how is it even possible to run models locally?
There are various tools available for running AI models on your local machine. In this tutorial, we’ll be using a tool called Ollama, which allows you to install and run models available in the Ollama model library. However, to make things easier, we'll use a pre-configured Docker image of Ollama that comes with pre-installed models (both embedding and LLM), so you won’t need to install anything manually. It's worth noting that many other tools can run models locally, each with its own advantages and limitations.
Can I Run ChatGPT, Claude, or Amazon Titan Locally?
Unfortunately, no. The weights of these models are proprietary and not publicly available, meaning they cannot be run locally. Instead, we rely on “open-weight” models, such as Llama. You can find Llama models in the Ollama library or on Hugging Face.
Great! So I Can Run an Open-Weight Model Locally and Get the Same Performance as ChatGPT?
Not quite. One of the key factors that affect a model's accuracy is the number of parameters it has. While the exact number of parameters in ChatGPT-4 is not publicly disclosed, various sources estimate it to be around 1.8 trillion parameters.
For comparison, I tried running llama3.1, which has 8 billion parameters—about 225 times fewer than ChatGPT-4. The result? It felt significantly less accurate, and my MacBook Pro, with 16 GB RAM and 6 Apple M2 Pro CPU cores allocated to Docker, struggled to handle it. The fans made scary noises, and the model ran extremely slowly (note: I was using the CPU, not a GPU).
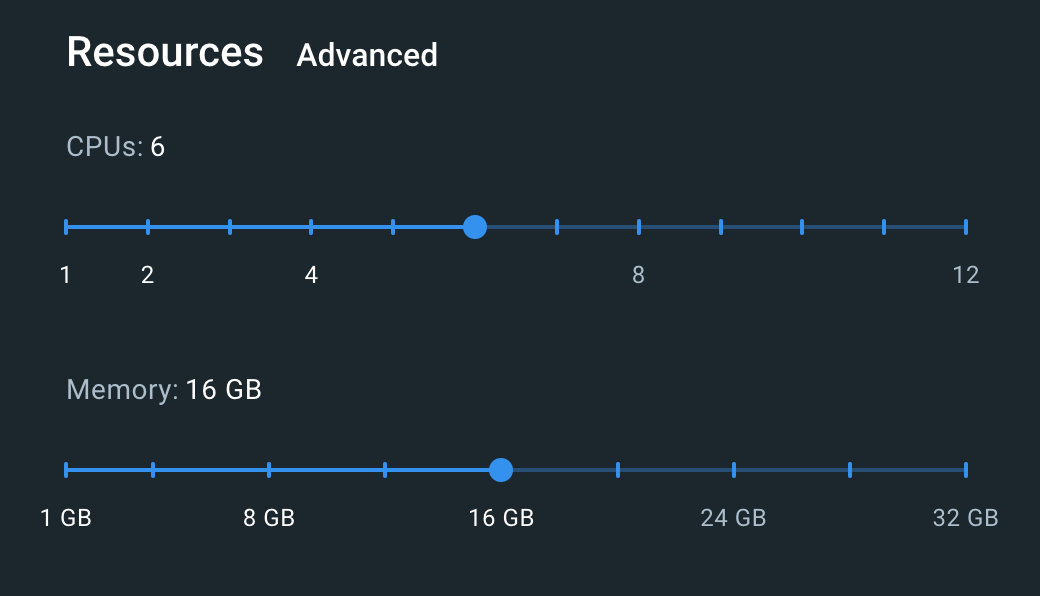
It's important to choose a model that matches your hardware capabilities. Additionally, when we pay for LLM services such as ChatGPT or AWS Bedrock, we're not just paying for the model itself but also for the infrastructure—powerful hardware, optimized backend services, and user-friendly interfaces that enhance the overall experience.
Implementing Local Model Support
To use a local LLM or embedding model, specify a model from the Ollama model library under the LLM_MODEL_ID and EMBEDDING_MODEL keys in the configuration file, following the ollama keyword.

Important: Ensure that the selected LLM supports tools for compatibility with the existing architecture. If you modify the default values, don’t forget to update the LLM and EMBEDDING_MODEL arguments in docker-compose.local-models.yml.

Once you've made the necessary changes, run the following command to start the Docker container with Ollama models and the open-webui interface for testing:
docker compose -f docker-compose.yml -f docker-compose.milvus.yml -f docker-compose.local-models.yml up --build
After the container is up and running, you can access the UI at localhost:8082 to experiment with your models.

If you find that your local models lack accuracy, consider replacing at least the embedding model with a local one. For example, mxbai-embed-large, which has only 300 million parameters.
Conclusion
In conclusion, running RAG models locally is now more accessible than ever, thanks to tools like Ollama and pre-configured Docker images. While proprietary models like ChatGPT or Claude cannot be run locally, open-weight alternatives such as Llama provide a viable solution for experimentation and development. However, it’s important to keep in mind that the performance of these local models may vary based on hardware capabilities and the number of parameters in the chosen model. By carefully selecting appropriate models and configurations, users can create an efficient and functional local setup without relying on costly LLM services.