
A RAG ChatBot to answer questions about New York City urban planning via API
A tutorial on setting up file ingestion using the open-source RAG-base repo

In this tutorial, we'll set up a RAG-powered chatbot API that answers questions about the New York City Planning Commission (CPC) reports. We'll be able to send in questions via the API and get back streaming responses.
The end result will look like this:

In the image above, chat_sync is a Python function that calls a streaming API that returns answers from the LLM.
This tutorial assumes you know the basics of what a RAG application is, what a vector database is, and a few other key ideas. It is a technical tutorial meant to guide someone working with our open-source RAG-base project for the first time.
Overview of our solution
Our goal is to have an API that we can send prompts to, and will respond using an LLM, feeding the LLM any relevant documents before it generates a response. For that, we'll need the following components:
A basic API that lets us send questions and answers via LLM.
An LLM model or LLM provider.
A Vector database that has loaded into it the NYC CPC reports.
This DB will be queried every time the user sends the API a question, and relevant documents will be fed into the LLM.
We're going to use our open-source RAG-base project to quickly get set up with a basic RAG application. This will set us up with an API that we can send questions to, and will use the LLM to answer. It will also query the vector DB for relevant documents to feed into the LLM. Of course, the vector DB at this stage will start off empty - we'll see that user questions asking for details from the reports won't return any relevant results.
We'll then load in the NYC CPC reports, and see that afterwards, the API returns relevant answers.
Running the base project
We'll clone the RAG-base project:
git clone git@github.com:hipposys-ltd/RAG-base.gitWe first need to set up our .env file, as per the instructions in the repo's README. Follow the instructions there to set up your LLM provider credentials (OpenAI or AWS Bedrock are supported as of this writing).
Once these are set up, we'll start the base project running with the command:
docker compose -f docker-compose.yml -f docker-compose.milvus.yml up -d --buildThis well get the project running with your chosen LLM provider, and with Milvus as the vector DB (this is the “default” option, but can be changed).
After the project is running, you should be able to immediately ask questions to the LLM via the API, as explained in the project README file. We'll ask a question we know appears in one of the CPC reports, and expect the current LLM to now know how to answer it.
Our question will be: "What are the changing conditions of the Special Hudson Yards District?". We'll ask it via curl to the API, as laid out in the README:
curl \
-i \
-X POST \
--no-buffer \
-b cookies.tmp.txt -c cookies.tmp.txt \
-H 'Content-Type: application/json' \
-d '{"message": "what are the changing conditions of the special hudson yards district?"}' \
http://localhost:8080/chat/ask
We can see that part of the response is:
I | apolog | ize, | but it | seems that | our | internal | company | database | doesn | 't contain | any specific | information about the changing | conditions | of the Special | Hudson | Yards | District | . The search | results | returne | d information | about | A | esop's f | ables, | which | is | not | relevant to your | question. |
Given | the | lack of relevant information | in our database, | I cannot provide a | detaile | d or | accurate | answer about | the changing conditions of | the Special Hudson | Yards District.This response is of course expected, as we haven’t loaded in the reports yet, so the LLM has no knowledge about this topic.
A note about the pipe characters (|) you can see in the response - the server sends the LLMs answer via streaming, so we can start seeing the answer right away, similar to how ChatGPT works. To make the separation between messages clearer in local mode, we add the “|” character in between each message received by the server. In a production setting, each message from the server will actually be a json response which bundles both message metadata and the textual response, but in local mode we only show the textual response.
Loading the reports
We now want to load in the CPC reports to the vector DB. We'll do this via a Jupyter notebook that will process the PDFs and load them in to the vector DB.
Connecting to Jupyter labs
First, as part of the initial run of the RAG-base , a Jupyter labs instance should be running inside it. We can connect by going to http://localhost:8890/lab/.
The first time we try to connect, we'll need a token. We can find it by viewing the logs of the running Jupyter container:
docker logs jupyter -fWe should see a few lines like these, with some token number indicated by {TOKEN}:
To access the server, open this file in a browser:
file:///home/jovyan/.local/share/jupyter/runtime/jpserver-8-open.html
Or copy and paste one of these URLs:
http://{url}:8888/lab?8k
http://127.0.0.1:8888/lab?token={YOUR_TOKEN}Once we have the token we'll be able to log into the Jupyter server, and we should we the Jupyter Labs interface.

On the left-hand side, we have our file browser, and we'll navigate to work/notebooks, where the example notebooks are located.
Chatting via Jupyter notebooks
We should now be looking at a few files:

Let's start by loading up the notebook chat-via-api:
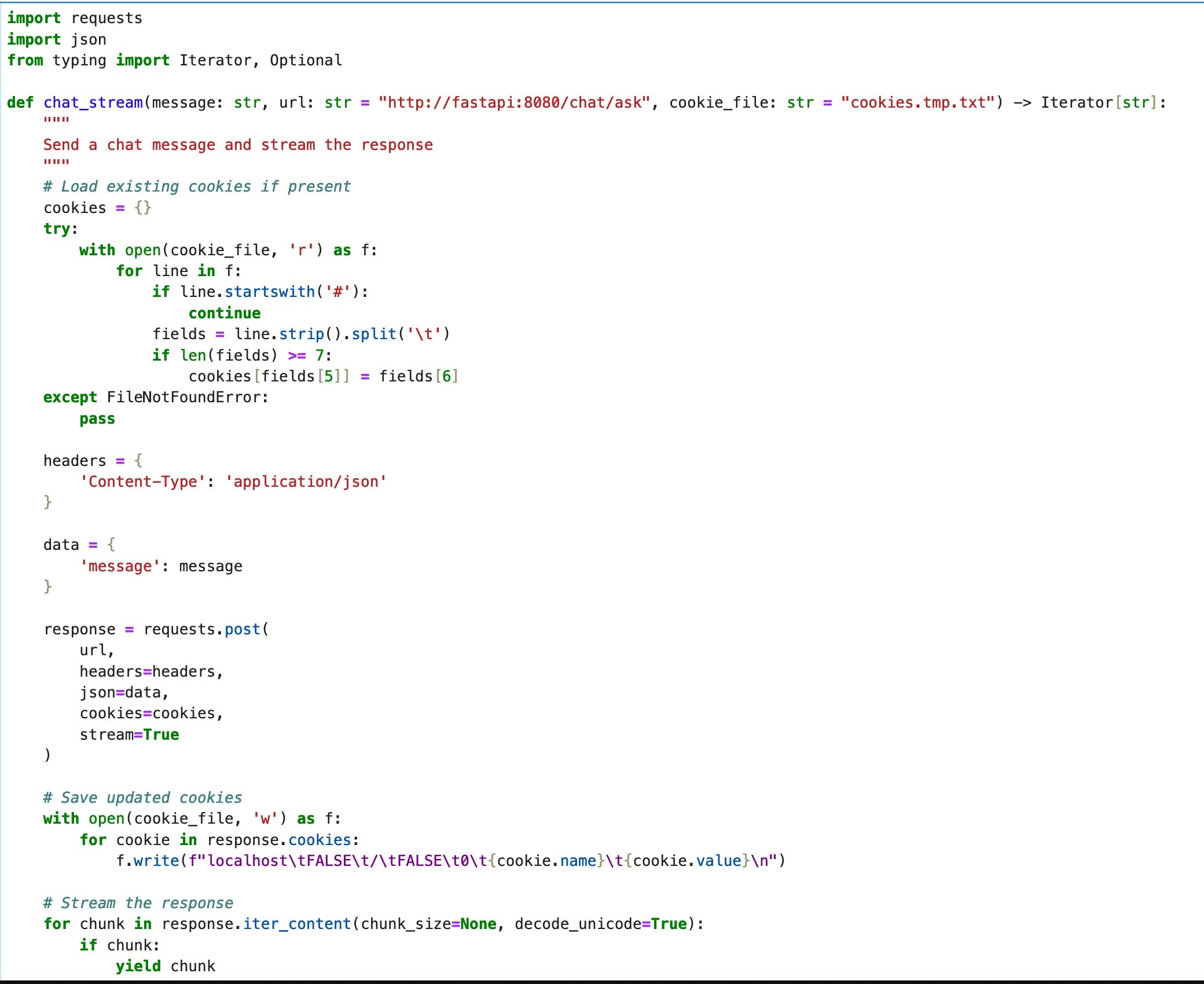
In it is a simple function that lets you send chat queries to the API, which is sometimes more comfortable than using curl via the command line (though you can of course continue to use the command line).
Run the first two cells, then run the last cell which contains a chat query. We'll ask the same question we asked earlier via curl, and should receive a similar response:


Loading in our data
We'll now load in our NYC CPC file data via a separate notebook.
First, we'll need to get some reports to load in. For this tutorial, I've manually downloaded some report files from the CPC website. You can find a zip file of the reports that I downloaded here.
These reports are in PDF format, and we can see for example that one of them has information that is relevant to our search query:
From 100119.pdf:

We'll now load the reports into the vector database. We can theoretically do this via our API, but in cases of bulk-loading files, it is more likely that we'll want to process and load them directly, as it is often a very long process that happens rarely. In a production scenario, we can use the bulk-load method to load the files initially, and the API for daily updates as we get new files or changes coming in.
To start, let's open the notebook file-ingestion.ipynb. It contains helper code and functions to load in various files from our project's data folder.
We should run the first few cells, up to and including all the cells in the section titled Ingesting Documents:

To make things easier, we are assuming in this tutorial that we'll have separate folders inside of our data folder that contain only a single file type, like pdf. In this cell, we define a function called get_splits_from_paths, which gets a file path and a specific Loader object which knows how to load the files in the path. We then define specific functions for loading .txt files, .pdf files and .docx files.
We'll now need to set up our folder. Inside our repo, there is a folder called data, which is mounted via docker as part of the repo, so anything we put in there is accessible to the notebooks. We'll copy our report pdfs in there. For starters, we'll copy three report files, including one that has data about our query. We're putting them in a subdir of the `data` folder called `ny_cpc_reports`, as you can see below.

To actually load these files into the vector db, we'll go to the section of the notebook titled Ingesting PDF documents . We need to make sure to change the name of the sub-folder in the first cell, then we can run the two cells there:

This may take some time to finish running.
The first function gets all the splits from the pdf files, meaning it uses langchain's PDF loader to load the PDF and extra the text from it, then splits the text into chunks that can be inserted into the vector db, as you can see in the definition of the file.
The next function adds the splits themselves into the vector db.
Note that in a production scenario, there are a few things we'd probably do differently:
We wouldn't load into memory all the pdf files at once as splits, before inserting them in the vector db, as we might be dealing with far too many files to handle in memory at once.
We would probably be doing more processing than simply reading the reports and dumping them in directly.
There are many techniques that have been developed to improve the results of a RAG system, and more techniques are being developed every day.
2. We will have tutorials in the future showing some of these more advanced techniques.
Testing our question again
We are now ready to ask our question again.
We can open up the chat-via-api.ipynb notebook again, and rerun our question (we can put it in a separate cell if we want to compare the previous answer to this answer):
If everything worked correctly, the response should now include a reference to the file 100119.pdf, and the chat response will include information gathered from that file:

Conclusion
We’ve shown how to set up a simple RAG-enabled chatbot API that lets you answer questions about any PDF files you want to load in.
Looking for help with your own RAG project? Feel free to reach out to us for a free consultation at rag-consult@hipposys.com.