
Demystifying RAG: The Technique Powering Modern AI Products
How to Connect AI to Your Business’s Data

When companies dive into building a Generative AI (GenAI) product, one of the first questions they ask is: “How can I connect AI to my company’s documents?”
If they’ve done a bit of research, they’ve probably encountered terms like “fine-tuning,” “vector databases,” and “RAG.” While these buzzwords can sound intimidating, RAG is actually much simpler than it seems—and it’s often the best place to start. We talked a bit about when to use RAG in a previous post:

In this post, we’ll break down what RAG is, how it works, and why it’s such a practical tool for integrating AI with your business data. Along the way, we’ll share examples and highlight the key challenges (and opportunities) when building a RAG-based system.
What is RAG?
RAG stands for Retrieval-Augmented Generation. At its core, RAG is just about combining two techniques:
Retrieval: Finding relevant information (e.g., documents) based on the user’s query.
Generation: Using a language model (LLM) to generate a response, with that retrieved information included.
In simpler terms: RAG feeds your AI extra context so it can give smarter answers.
RAG is the technique of finding and adding relevant context to an LLM, before generating a response.
Here is the simple overview of the two parts of any RAG system:
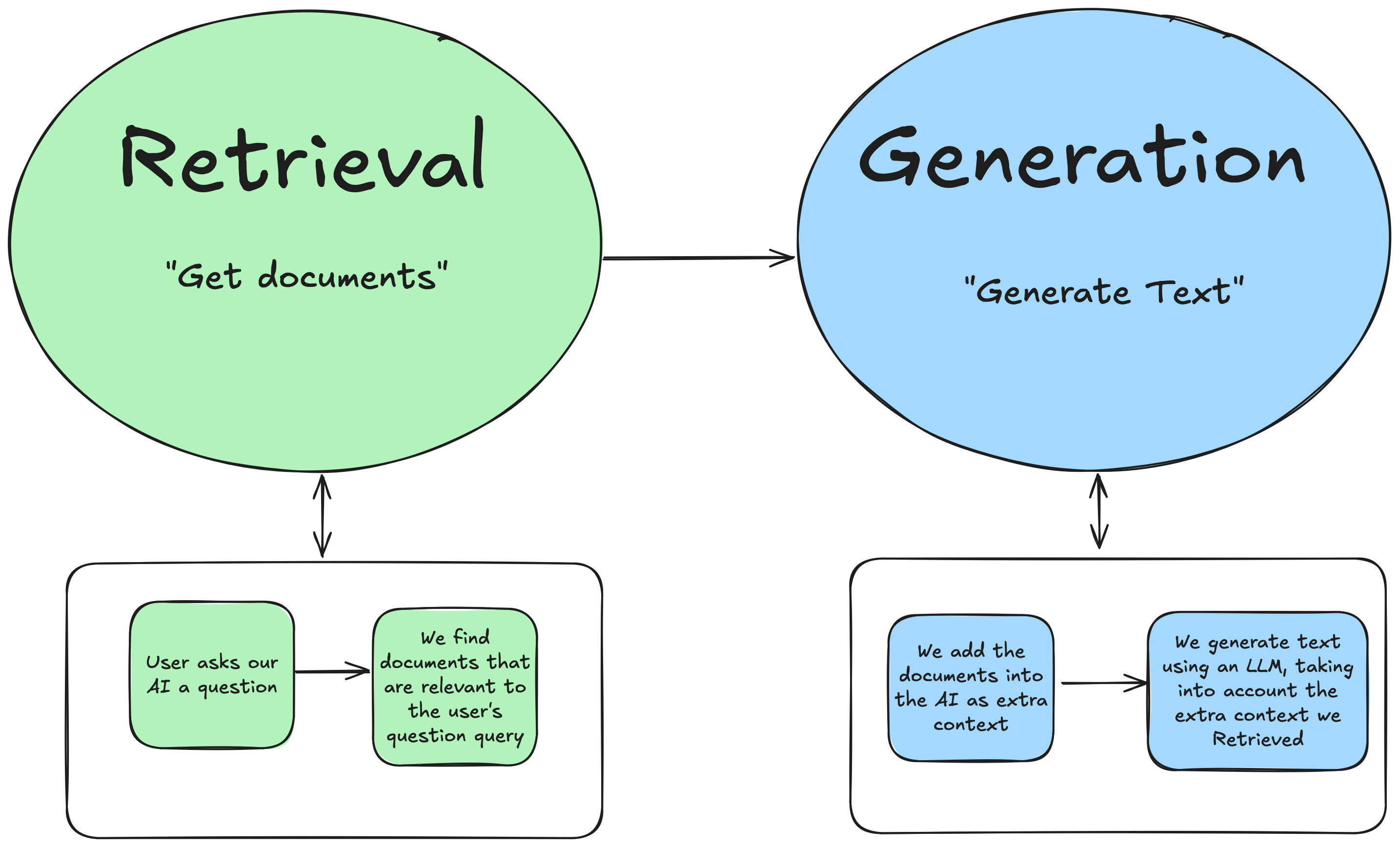
Both Retrieval and Generation are interesting technologies! And they’re both important parts of the process. They’ve also both become much better with the rise of LLMs (Large Language Models). They are two separate, but equally important parts of the process.
Using retrieval combined with generation is what makes RAG so powerful—it bridges the gap between your data and the AI’s capabilities.
In practice, the technique can get very complicated, because how to find relevant context can be challenging, because generating the right response is challenging, and because of other technical issues.
A Quick Example: RAG in Action
Let’s make this concrete with an example. To start, we’ll look at generation, which is what most people are familiar with from using a tool like ChatGPT.
Asking ChatGPT Without Context
Suppose we ask ChatGPT a question about Alice’s Adventures in Wonderland:

Nice! The model gets it right because it “knows” about Alice in Wonderland. But what happens if we ask a more specific question, one that the model might not have enough information to answer?
Let's ask a harder question and see how we fare:
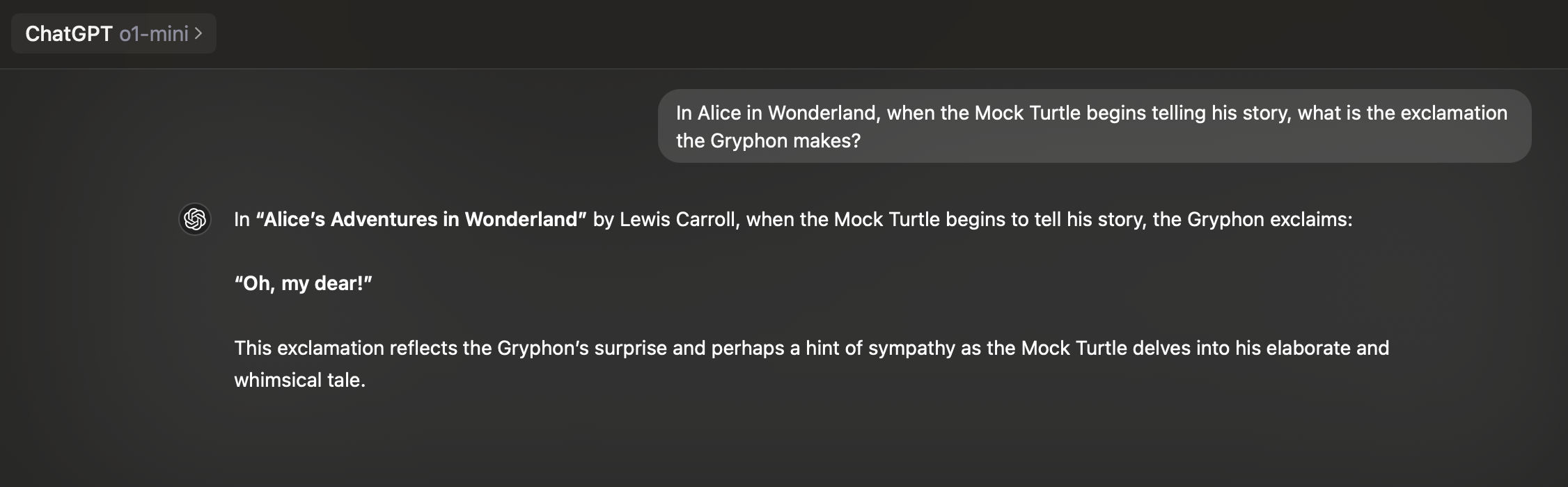
Oops. That’s not correct. Why? The model still understood my English perfectly well, it answered in the way a human might answer. But it either didn’t have the right details in its training or didn’t recall them accurately.
Adding Context: RAG to the Rescue
Let’s try again, but this time we’ll add some relevant context; we’ll copy the exact passage from the book that answers the question and include it in the prompt. This is the passage:

Let’s try including it in the prompt:
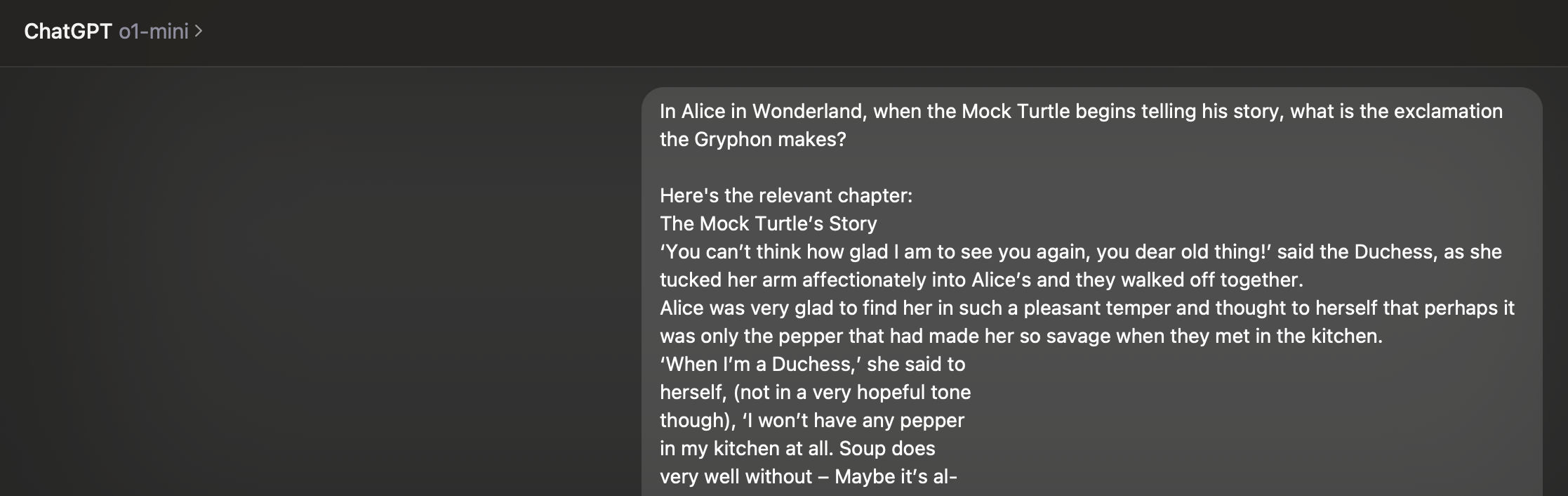
And here is the result this time:

Much better! With the right information included, the AI gives the correct answer.
This is the essence of RAG: retrieving the right context and feeding it to the AI. Of course I totally cheated here - I knew exactly what context was relevant, and manually pasted in in. In a real-world application, you wouldn’t want to copy-paste documents manually—you’d look to automate this process.
How RAG Works in Practice
This shows us the idea behind RAG. In practice, RAG can be hard to get right, because:
Retrieval is hard. You need to find the most relevant information for a user’s query, often from a massive pile of documents. It’s not always clear what “most relevant” even means - it’s often a judgement call based on knowing the business context.
Generation is also hard. We don’t talk about it much in this post, but this can vary widely depending on what exactly is being generated (chat responses? Contracts? Book reviews?).
I want to emphasize this again, because this is something people often miss about RAG:
The Retrieval step in RAG - finding the context that’s relevant to a user's query - is a hard problem, and it's distinct from the hard problem of generating text.
In practice, when building an AI product, both of these are problems that need to be worked on.
Automating Retrieval
At its core, Retrieval is about finding “the good stuff” in your company’s data. While you could theoretically use simple search algorithms, when talking about modern RAG systems, people usually mean these common techniques:
Document embeddings: Turning text into mathematical representations for smarter matching.
Vector databases: Storing document embeddings in a format optimized for fast retrieval.
Semantic search: Finding documents based on meaning, not just keywords.
These tools allow us to go from a chat-style user prompt, to documents that are relevant to that prompt (as opposed to traditional, keyword-based search).
We won't go into detail on the mechanics of these techniques, or how the retrieval interacts with the Generation step and gets added in to it - we will explore those topics in a future post.
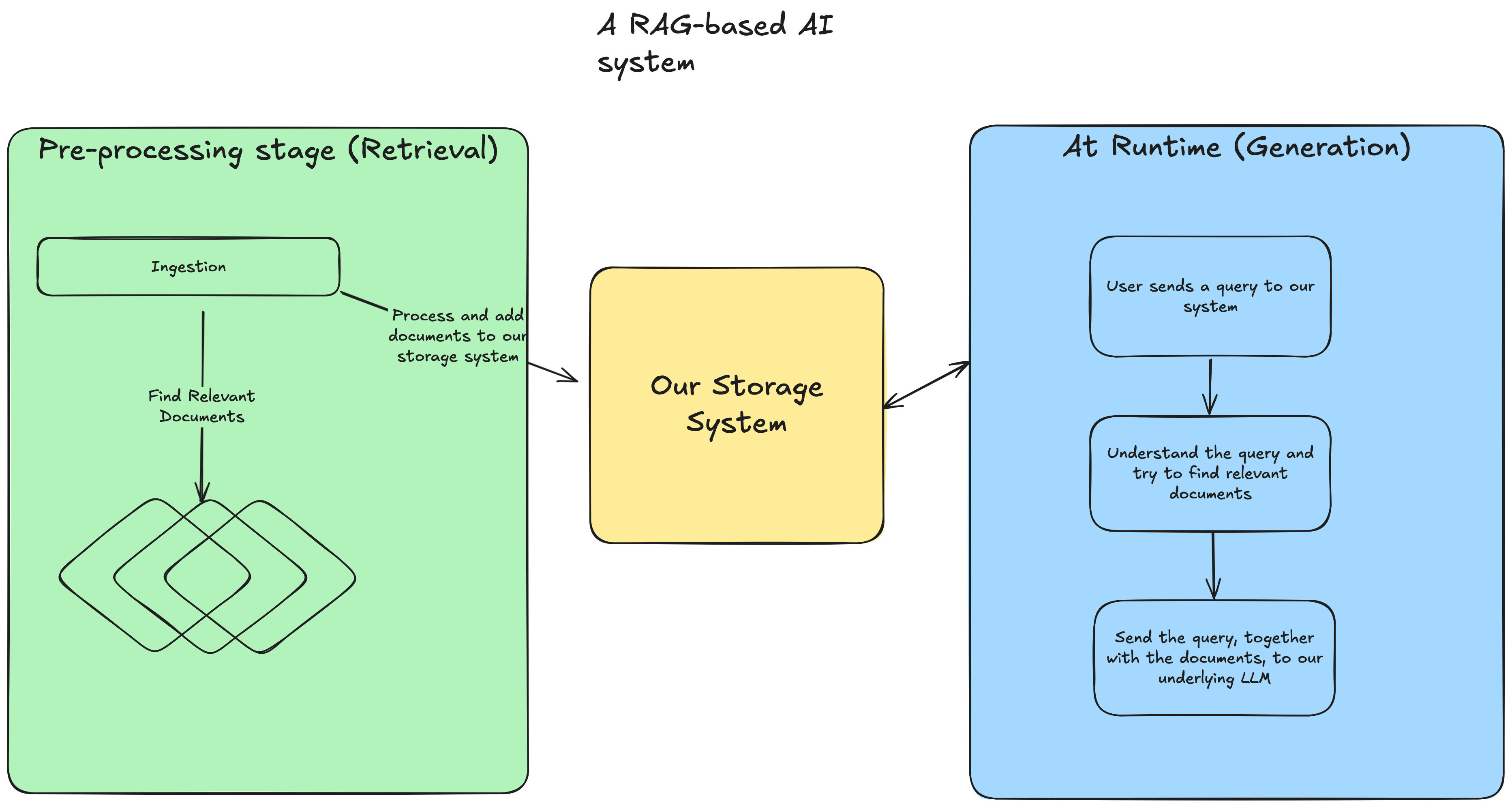
The RAG Workflow
Here’s what a typical RAG system looks like in practice:
Ingestion and Preprocessing
Collect all your relevant documents (e.g., PDFs, wiki pages, emails, database entries).
Preprocess the data into embeddings and store them in a vector database.
Query + Retrieval + Generation
A user submits a query.
The system retrieves the most relevant documents from the database.
These documents are fed into the LLM, which generates the response.
The Data Engineering Side of RAG
Building a RAG system isn’t just about plugging in an AI model—it also requires robust data engineering. Here are some key challenges:
Collecting and Organizing Data
Your documents might be scattered across multiple systems (e.g., PDFs, CRM records, email archives). You’ll need to centralize and organize them.
Keeping Data Fresh
New documents will need to be added.
Old or irrelevant documents must be removed.
Updates to existing documents should be reflected in real time.
Metadata Management
Adding metadata (like timestamps or document categories) can improve retrieval. For example, prioritizing recent documents might give better results for certain queries.
Why RAG Matters
Why RAG Matters
RAG is a game-changer because it allows businesses to combine the general knowledge of LLMs with their own proprietary data. Instead of training a custom model from scratch (a costly and time-consuming process), you can focus on retrieving and integrating the data your AI needs to perform better.
It’s not magic—but it can feel like it when it works seamlessly - usually after a lot of effort into working on retrieval and generation.
What’s Next?
In this post, we covered the basics of RAG - from code principles, to implementation. In future posts, we’ll dive deeper into topics like retrieval techniques, scaling RAG systems, and the interplay between data engineering and AI.
Stay tuned—you’re just scratching the surface of what’s possible with RAG.
Need help with your own AI or Data Engineering needs? Reach out to us at contact@hipposys.com. We’d love to talk with you!