


Introduction
DBT is a powerful tool for transforming data and managing analytics engineering workflows. But let’s face it—while it’s great for developers, it can be tough for analysts, product managers, or even other engineers to understand exactly what’s happening inside a specific model. The SQL can get dense, the logic isn't always obvious, and while DBT Docs and DBT Cloud’s Explore are helpful, they fall short when it comes to things like query-level lineage or automatic explanations of what a model is actually doing.
That’s why we built DBT to English—a tool that gives you LLM-powered insights into your DBT project. Whether you're using Bedrock or Anthropic, you can plug in your preferred LLM and get clean, contextual, human-friendly interpretations of your models, SQL logic, metadata, and lineage. Plus, it’s fully customizable: tweak the system prompt to get documentation that fits your team’s voice and style.
In this blog post, we’ll walk you through how to get started with the tool and show you how it can bring clarity and accessibility to even the most complex DBT projects.
Running Locally
To get started, clone the repository: https://github.com/hipposys-ltd/dbt-to-english
Then, copy the environment template file and create your local .env configuration:
cp private.env-template private.envIn your .env file, set the LLM_MODEL variable depending on the provider you're using:
For Anthropic models, start the value with Anthropic: and provide your ANTHROPIC_API_KEY.
For Amazon Bedrock, start with Bedrock: and include your AWS credentials and connection settings.
Once configured, build and start the app with Docker:
docker compose up --buildAfter it’s running, open your browser and go to http://localhost:8501/ to access the Streamlit interface.
DBT to English Translation
When you open the UI, you'll see a form that asks for two files: catalog.json and manifest.json.
If you don’t have your own DBT project, you can use sample files from our repository:
DbtExampleProject/target/catalog.json and DbtExampleProject/target/manifest.json.
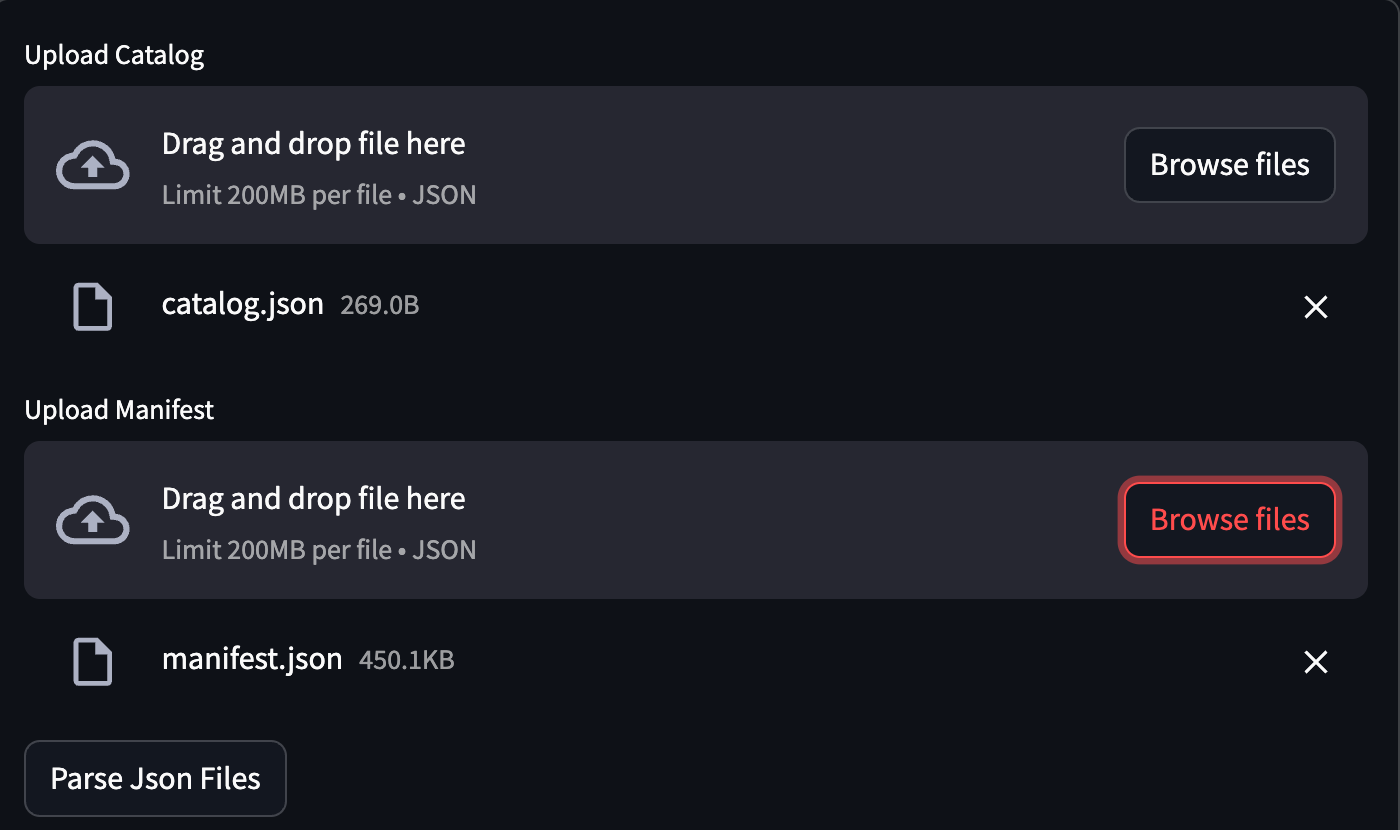
Once you've selected the files, click on “Parse JSON Files.”
This will reveal two additional fields:
A field to select the nodes (models) you want to parse or generate documentation for.
A System Prompt field that defines the instruction sent to the LLM.

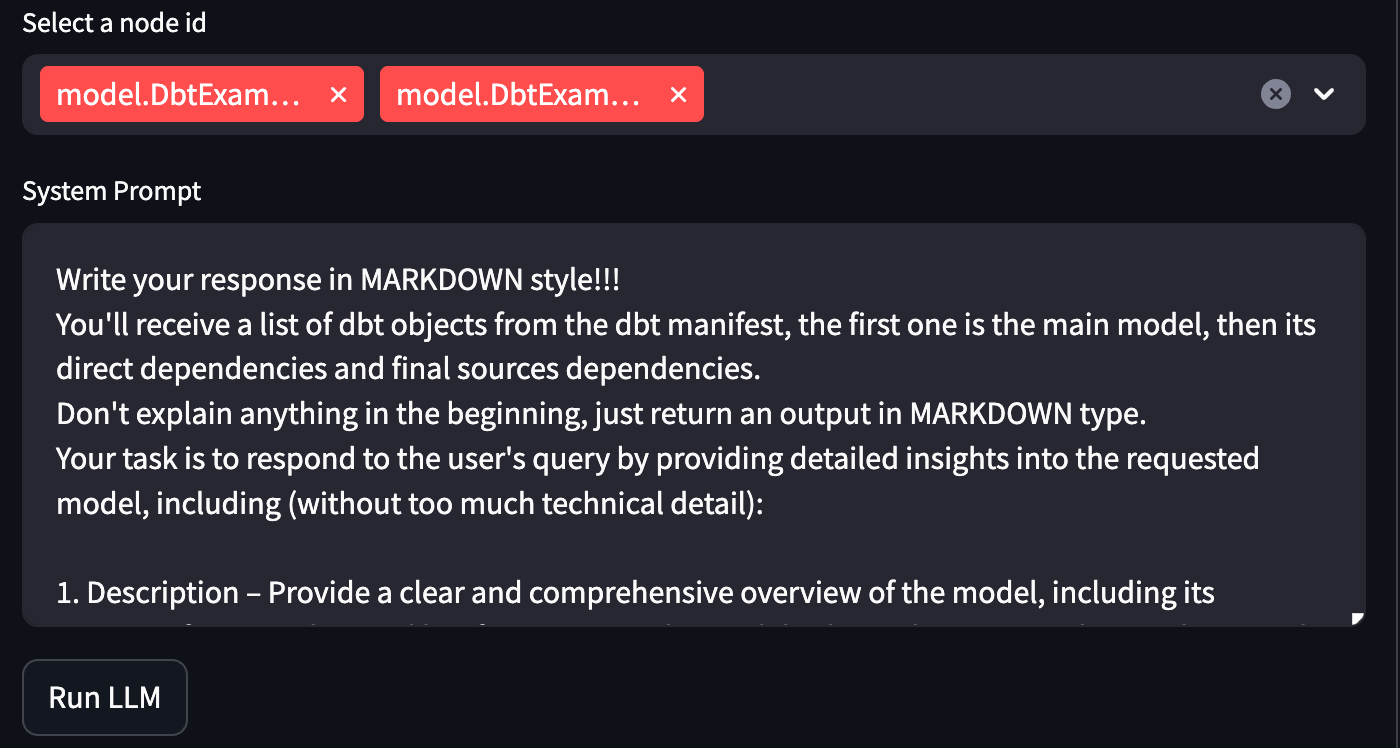
Choose a few models and leave the System Prompt as-is for now, then click “Run LLM.”
You’ll receive a detailed, plain-English explanation of your selected model.
First, you'll see a natural language description—no SQL syntax or complex calculations.

Next, an interactive graph will be generated. Unlike dbt Docs or dbt Cloud, this graph includes not just model-level lineage but also internal relationships like CTEs and calculations.
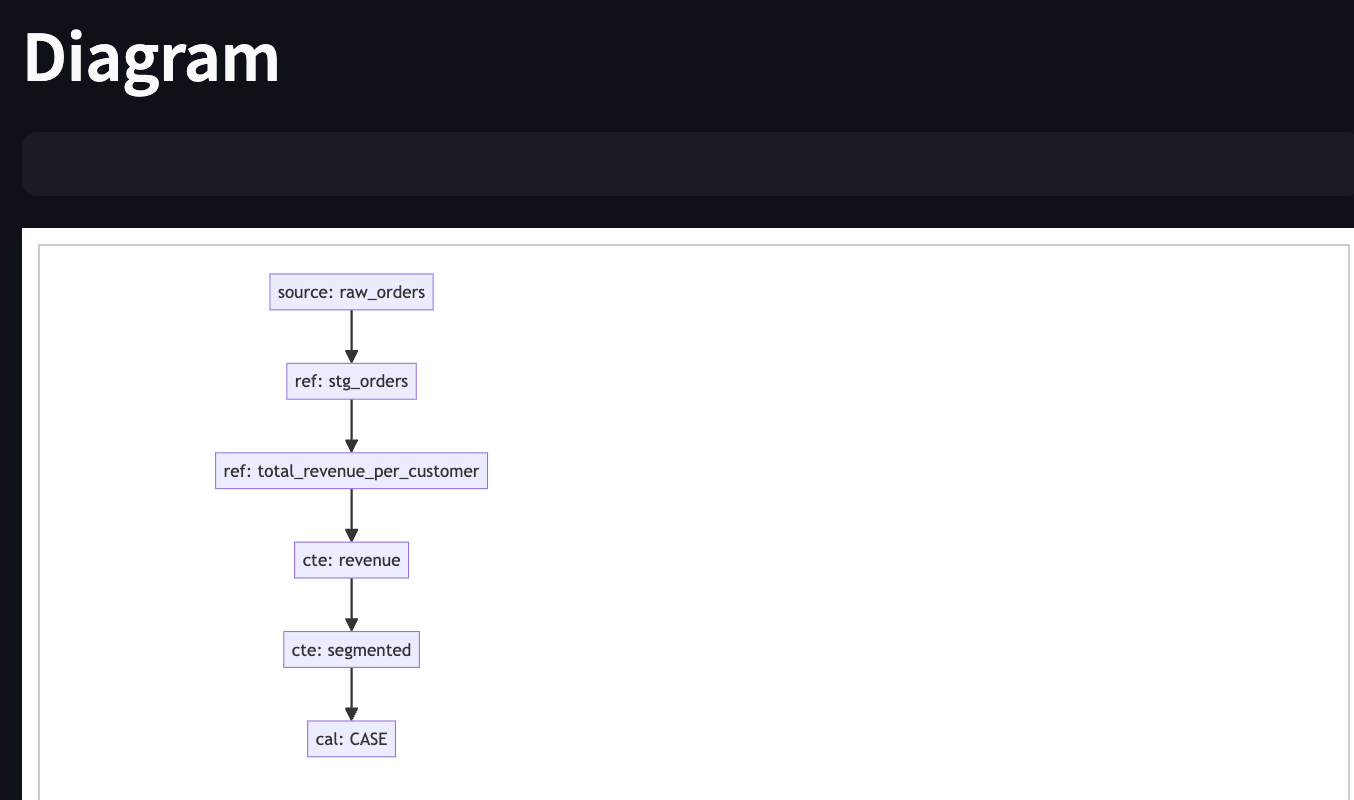
Following that, SQL Logic & Calculations and Columns Table will show how each column was derived, including its source tables.


Finally, you'll see a Dependencies Table with brief explanations for each dependency.

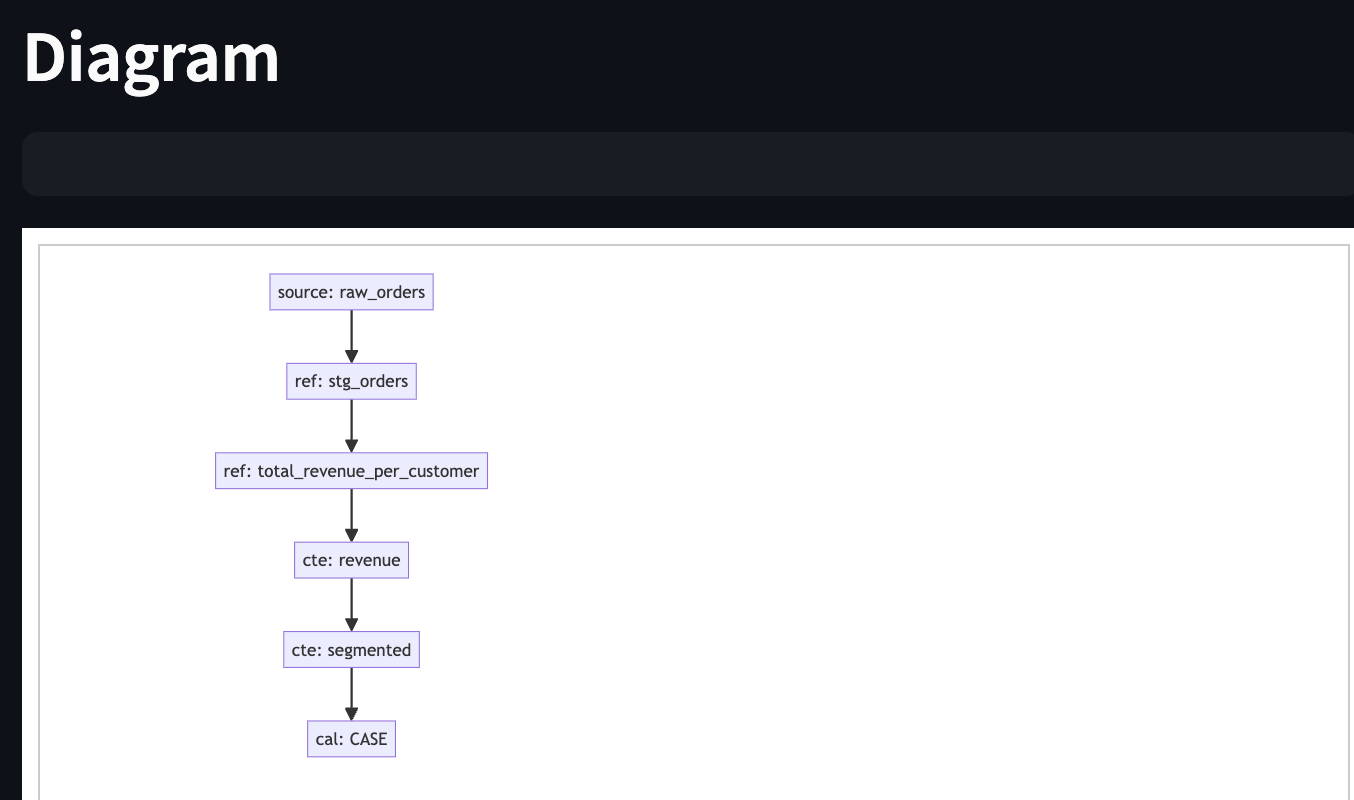


Pretty cool, right?
Want to change the output?
Perfect! That’s exactly what the System Prompt is for. Let’s go back to it and take a closer look.

The response you received was directly shaped by the System Prompt. Feel free to experiment—change the structure, add your own instructions or formatting, rearrange the output, etc.
Important: If you modify the diagram-related instructions, please keep the example section as-is.
Our UI relies on that example to recognize the diagram portion in the LLM response and render it as an interactive graph.

Conclusion
"DBT to English" is our way of making DBT projects more accessible, understandable, and human-friendly—no matter your technical background. By leveraging the power of large language models, we’ve opened the door for teams to explore data models, understand complex SQL logic, and visualize lineage at a much more granular level—all through a clean, conversational interface.
But this is just the beginning.
We enthusiastically invite the community to contribute to this open-source initiative—whether you're interested in adding new features, supporting more LLM providers, improving prompts, or enhancing the UI. Your feedback and contributions will help shape the future of how we understand and interact with modern data stacks.
Visit our GitHub repository at https://github.com/hipposys-ltd/dbt-to-english to join the project, submit pull requests, or share your ideas. Let’s make DBT more approachable!