
AWS S3 Vector Buckets Are Here — Use Them with LangChain
Connect the dots between Amazon’s new vector storage and LangChain’s RAG workflows

Introduction

When building a RAG system, developers often turn to vector databases—like ChromaDB or Milvus—for storing embeddings. While popular, these solutions come with notable drawbacks:
Proprietary options can be expensive, and even open-source databases typically require maintaining a full cluster.
Managing infrastructure—permissions, monitoring, uptime—adds significant operational complexity.
Scaling vector databases for large workloads isn't always straightforward or cost-effective.
Most solutions lack native integration with AWS services like Amazon Bedrock Knowledge Bases.
To address these limitations, AWS recently introduced S3 Vector Buckets—a lightweight, scalable, and fully managed way to store and retrieve vector embeddings directly within Amazon S3. While AWS provides excellent documentation on using this with their Agent ecosystem (official guide), we created a demo project showing how to integrate S3 Vector Buckets with LangChain.
In this post, we'll walk you through the setup, using real-world data from the NYC City Planning website, and demonstrate how to extract useful insights with natural language queries.
Setting Up the Vector Bucket
Start by navigating to AWS S3, selecting Vector Buckets from the left-hand menu, and creating a new bucket.
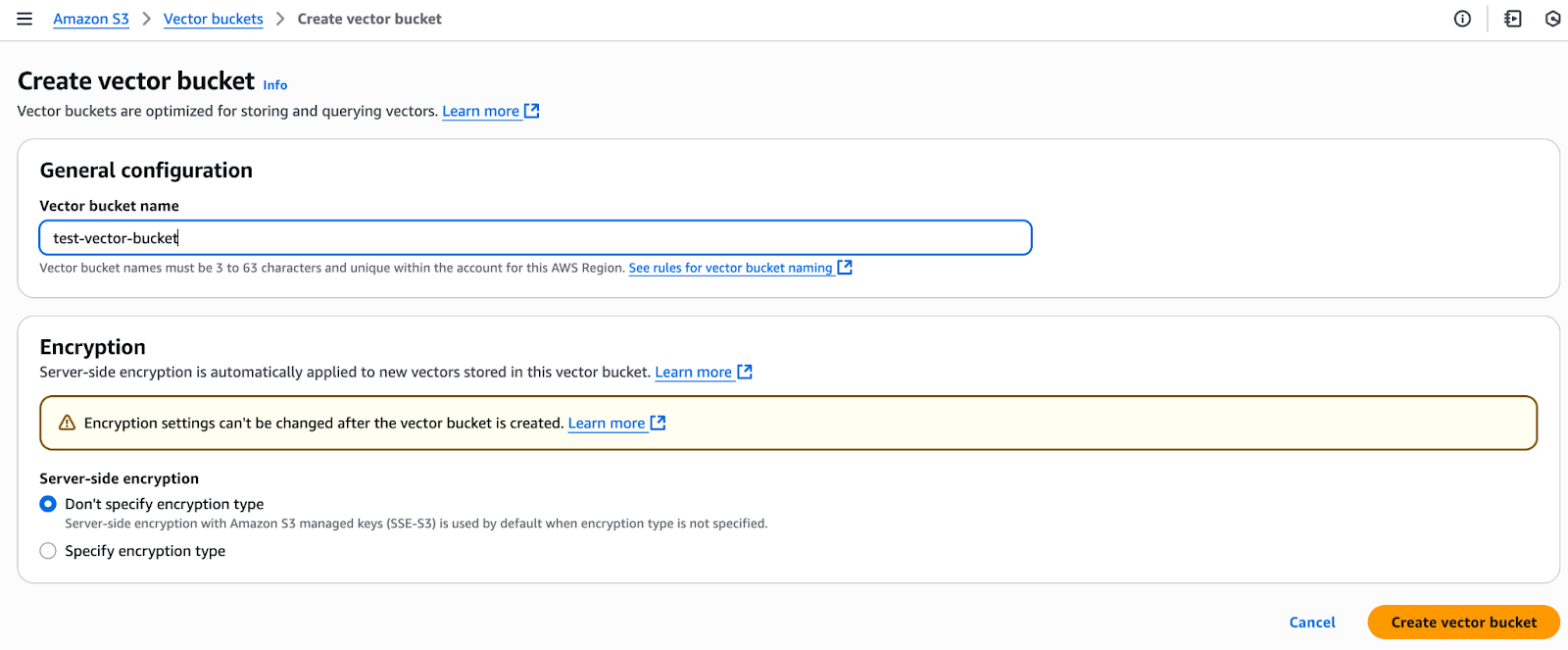
Great — now we have an S3 vector bucket ready to store embeddings. But how do we search through those vectors? For that, we need to create a vector index.

When configuring the index, set the dimensions value to match the number of values returned by your embedding model. Since we’re using the amazon.titan-embed-text-v2:0 embedding model from Amazon Bedrock, which produces vectors of 1024 dimensions, set the dimension accordingly.
Next, you’ll need to choose a similarity measure — either Euclidean Distance or Cosine Similarity. We’ll use Cosine Similarity, as it aligns better with how Titan embeddings are designed: they capture meaning in the direction of the vector rather than its magnitude, which is exactly what Cosine Similarity measures.
Perfect! With both the vector bucket and index set up, you're now ready to run your repository and start interacting with your vector store.
Using the Vector Bucket
To get started, clone our demo repository locally:
git clone https://github.com/hipposys-ltd/s3-vector-bucket
cd s3-vector-bucket
cp template.env .envThis will generate a .env file where you’ll configure all necessary environment variables:
DEPLOY_ENV='local'
# Postgres
POSTGRES_USER='postgres'
POSTGRES_PASSWORD='postgres'
POSTGRES_DB='postgres'
# LLM Model
LLM_MODEL_ID='bedrock:...' # or use 'anthropic:...' or 'openai:...'
# Secrets (replace in production)
SECRET_KEY='ThisIsATempSecretForLocalEnvs.ReplaceInProd.'
FAST_API_ACCESS_SECRET_TOKEN='ThisIsATempAccessTokenForLocalEnvs.ReplaceInProd'
# AWS Credentials
AWS_ACCESS_KEY_ID='...'
AWS_SECRET_ACCESS_KEY='...'
AWS_DEFAULT_REGION='...'
# Optional Keys
# ANTHROPIC_API_KEY='...'
# OPENAI_API_KEY='<YOUR OPENAI API KEY>'
# Vector Store
bucket='test-vector-bucket'
index='test-vector-index'
# Optional: Custom embedding model
# embedding_model='...'To use Bedrock for both embedding and LLM, set LLM_MODEL_ID to a string starting with bedrock: and ensure your AWS credentials are configured.
If you prefer using models like Claude (Anthropic) or OpenAI, set the respective API key and adjust LLM_MODEL_ID accordingly (e.g., anthropic:... or openai:...).
Once configured, run:
just allThen open your browser and navigate to
http://localhost:8501
You’ll find three tabs:
Main – a chat interface to interact with your vector store
Load File – to upload PDF documents and populate your vector index
See Vectors – to explore and manage uploaded embeddings
Initially, the vector store will be empty, so let’s add some data.
Download the prepared NYC CPC dataset from:
https://hipposys-public-assets.s3.us-east-1.amazonaws.com/newsletter-assets/NYC+Planning.zip
Extract the PDF files into the data/ folder. Then, go to the Load File tab and upload them.
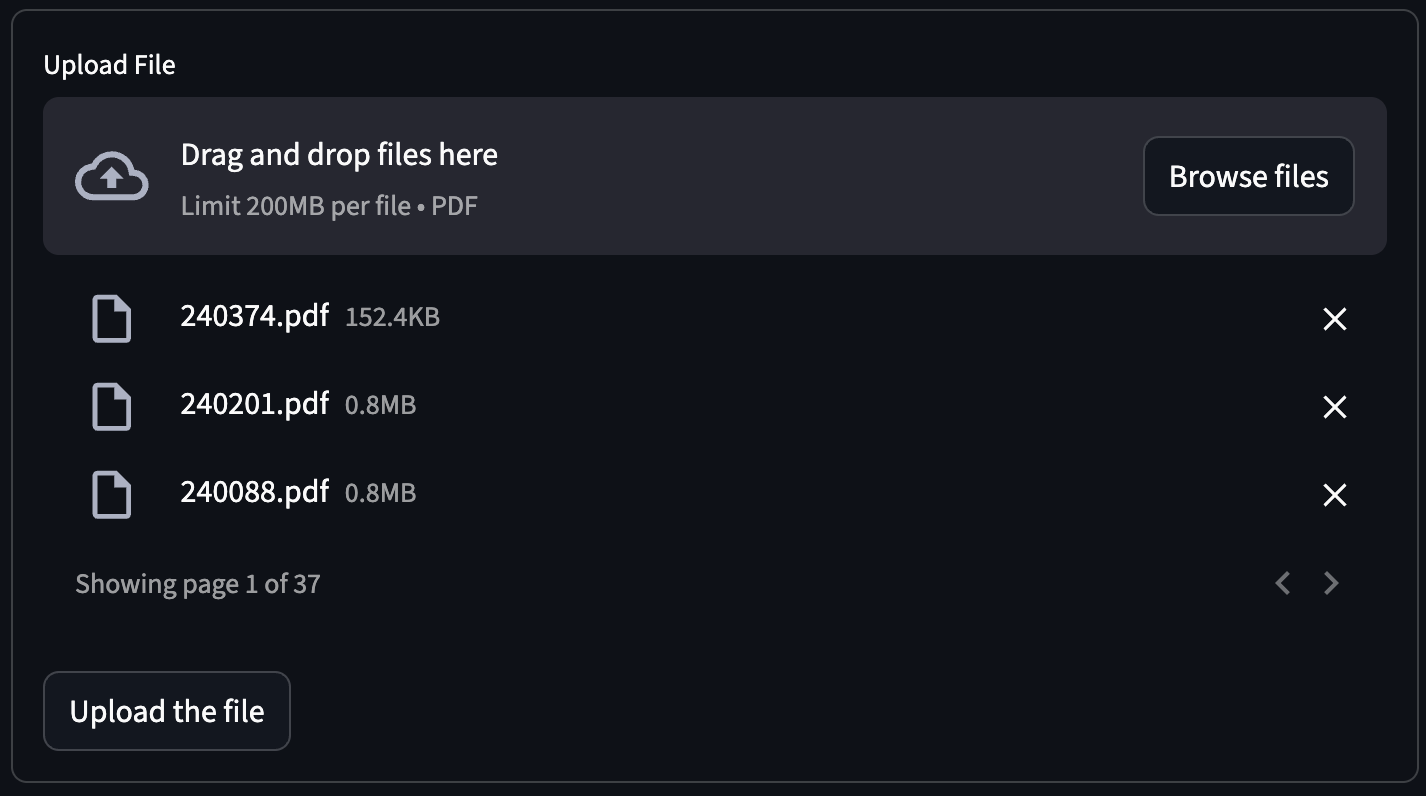
After processing is complete, check the See Vectors tab—you’ll see the loaded data! You can even manage the embeddings: delete individual rows, entire documents, or wipe all vectors.
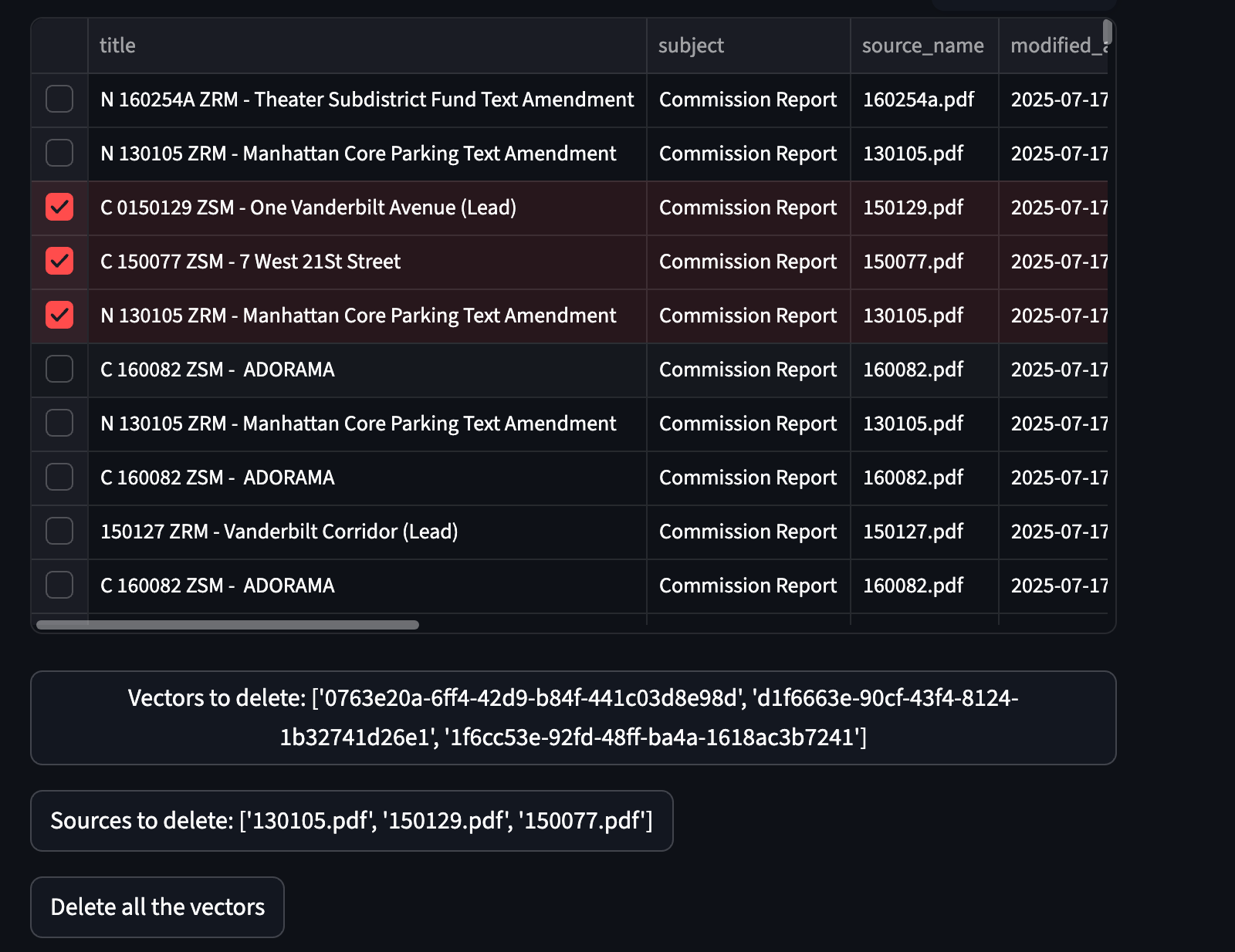
Now, switch to the Main tab and try a query like:
What are the changing conditions of the Special Hudson Yards District?
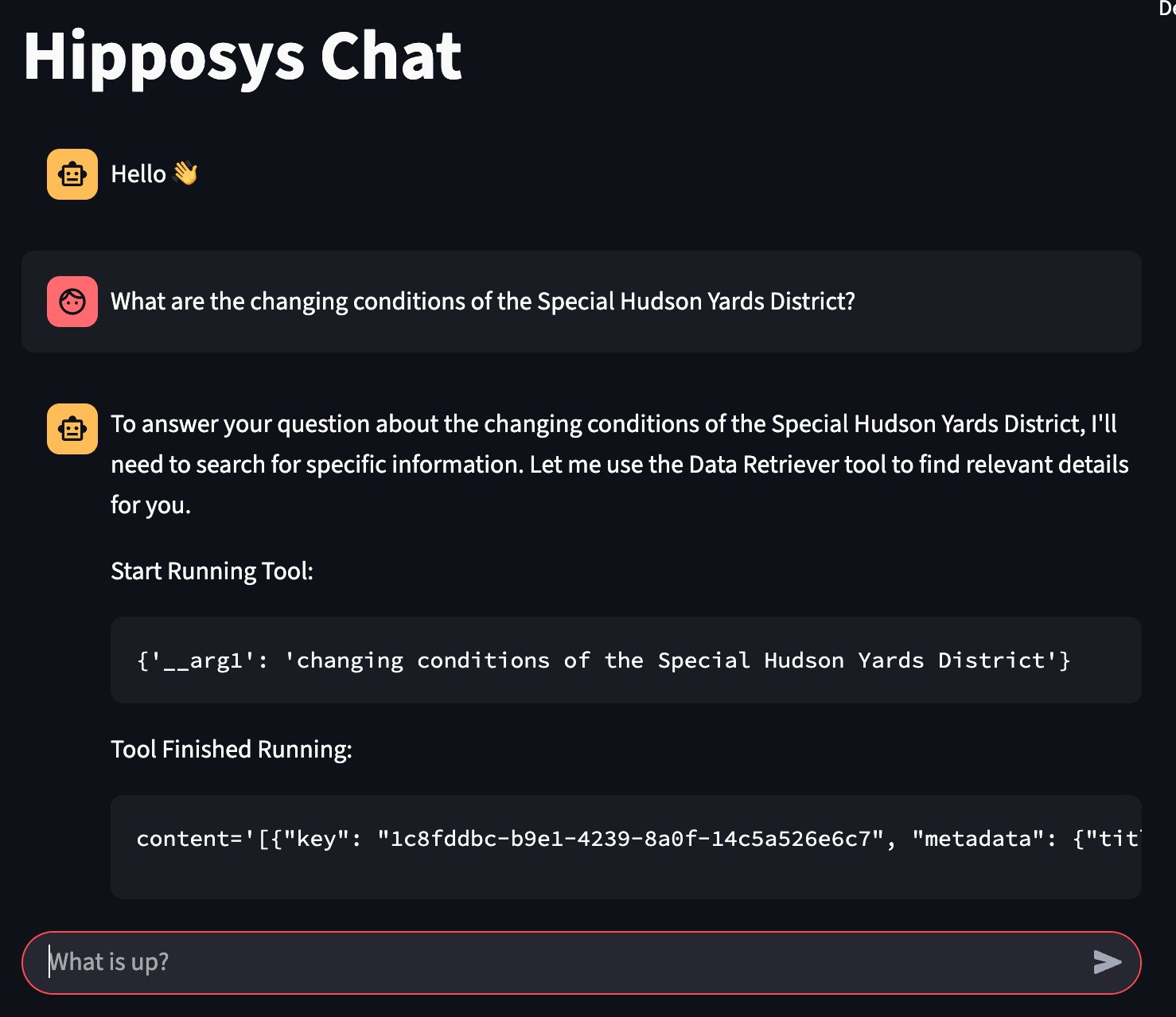


You should receive a highly relevant response—your setup is working!
How It Works
The core logic of our vector integration lives in app/vector/__init__.py.
Connecting to the S3 Vector Store
We use the boto3 SDK to interact with AWS’s new S3 vector store:
self.s3vectors = boto3.client('s3vectors', region_name='us-east-1')This client handles all interactions—storing, searching, listing, and deleting vectors in the configured S3 bucket.
Searching the Vector Bucket
The search method performs the following steps:
Embeds the input text using an embedding model (e.g., Amazon Titan).
Sends the resulting vector to the S3 bucket for similarity search.
Returns the top matches with metadata and distance.
def search(self, input_text):
request = json.dumps({"inputText": input_text})
response = self.bedrock.invoke_model(modelId=self.embedding_model, body=request)
embedding = json.loads(response["body"].read())["embedding"]
query = self.s3vectors.query_vectors(
vectorBucketName=self.bucket,
indexName=self.index,
queryVector={"float32": embedding},
topK=3,
returnDistance=True,
returnMetadata=True
)
return query["vectors"]Listing and Deleting Vectors
You can also view or clean up your vector store using the following methods:
def list_vectors(self):
query = self.s3vectors.list_vectors(
vectorBucketName=self.bucket,
indexName=self.index,
returnMetadata=True
)
return [{**vector['metadata'], 'key': vector['key']} for vector in query['vectors']]
def delete_vectors(self, vector_keys: list):
self.s3vectors.delete_vectors(
vectorBucketName=self.bucket,
indexName=self.index,
keys=vector_keys
)Uploading Data to the Vector Store
The upload_file function (also in the same module) handles:
Loading text from files
Generating embeddings
Storing them into the S3 vector bucket
This process is triggered when you upload documents via the Load File tab in the UI.
LangChain Integration
To integrate this logic into your LangChain agent, we wrap the search method as a LangChain Tool inside app/server/chat.py:
retriever = VectorDB()
tool = Tool(
name="Data_Retriever",
func=retriever.search,
description="Searches S3 vector bucket for similar embeddings and returns matching results",
)
tools = [tool]This enables your LangChain agent to retrieve semantically relevant data from your S3 vector bucket in response to user queries.
Conclusion
AWS S3 Vector Buckets offer a simple and scalable alternative to traditional vector databases—no clusters, no heavy maintenance, and no additional services to run. Combined with LangChain, you can now build RAG pipelines that are lightweight, cost-effective, and easy to set up.
Our demo showed how to embed and store documents, query them semantically, and retrieve meaningful answers—all using S3 as your vector store. Whether you're working with Amazon Bedrock, Anthropic, or OpenAI models, this setup provides a flexible and developer-friendly foundation for building intelligent applications.